
This is another batch scenario that is commonly used in line-of-business (LOB) application: extract-transform-load (ETL) or extract-load-transform (ELT). I would like to cover the fundamental CI/CD for Azure Data Factory first, so I am starting with data that is internet accessible: Azure Data Factory Batch Job (Public)
- Application has no access endpoint and runs on background in a preset interval
- Business logic processing is not required (or limited) *
- Data is served from one or more publicly accessible resource
- Processed result is stored in publicly accessible Azure Storage Account
- Data sensitivity is low, which has no or low impact to the organization
*If business logic processing is required, Azure Functions could be a better choice for encapsulating and/or reusing existing business layer components, please refer to Azure Function Batch Job with Storage Account (link).
Here are the areas I would like to demonstrate in this recipe:
- Use Azure Data Factory to host batch job with Schedule trigger for scheduling
- Add customized parameters per environment for Azure Data Factory
- Enable RBAC in both Storage Account with Managed Identity (MS Doc link)
- Demonstrate CI/CD automation with Azure DevOps using Bicep and YAML
You can find all the code in GitHub (link).
Application Example
As an example, this batch job downloads a dataset externally, transform it to CSV, and stores the result into Storage Blob. The job requires to run hourly and should take less than 30 seconds to complete. The implementation is to use an Azure Data Factory with Schedule Trigger and Storage Blob. Below diagram shows the deployment model into Azure Cloud:

Walkthrough
Azure Data Factory
In our context, we can treat Azure Data Factory (ADF) as a data integration platform-as-a-service. Similar to other Azure PaaS services, you could enable managed identity and choose to allow public access or not, below is the bicep code to provision ADF:
resource dataFactory 'Microsoft.DataFactory/factories@2018-06-01' = {
name: dataFactoryName
location: dataFactoryLocation
identity: {
type: 'SystemAssigned'
}
properties: {
repoConfiguration: dataFactoryRepoConfig
publicNetworkAccess: publicNetworkAccess ? 'Enabled' : 'Disabled'
}
}
In addition, Azure Data Factory also provides development tool with the ability linking to source control, which is required for CI/CD automation. The following sample shows the configuration to link to an Azure DevOps Git repo, and you can find out more at Microsoft documentation (MS Doc link):
var repoConfiguration = {
accountName: '<your ADO Org Name or GitHub User Name>'
collaborationBranch: '<name of your main branch>'
repositoryName: '<your repo name>'
rootFolder: '<the folder name used by ADF as its root folder>'
type: '<either FactoryVSTSConfiguration for Azure DevOps or FactoryGitHubConfiguration for GitHub '
projectName: '<your Azure DevOps project name>'
}
IMPORTANT: Linking to source control is only required for development environment, do not link upper environments (Test, Prod, etc.) to Git repo. In addition, Azure DevOps Git Repo must connect to Azure Active Directory, see Microsoft documentation for details (MS Doc link).
Azure Data Factory: Integration Runtime
Integration Runtime (IR) is the ‘engine’ to execute your ADF solution, such as pipelines, data flow, etc. When provisioning ADF, it comes with an Azure IR by default that supports data operation/integration in internet accessible network. You don’t need to explicitly create an IR unless you need to define the location of the IR or control the execution of certain activity on different IRs. Azure IR should be able to handle most of line-of-business application scenarios. There are two more types of IR: Self-Hosted IR, which is usually utilized for on-premises connectivity or specific connectivity requirements, and SSIS IR, which runs SSIS package for migrating SSIS to ADF.
Azure Data Factory: Development Approach
I am applying the same branching approach (see below) as in previous recipes to ADF development and using pull-request to merge from feature to develop, and develop to main. Therefore, the design for Azure DevOps pipelines is almost the same, except I need a ‘dedicated’ pipeline to provision the infrastructure. It is because an instance of ADF is required first in order to develop any ADF solution.
- feature branch: individual development via ADF Studio using Validate and Debug buttons
- develop branch: integration branch and source to deploy to Dev environment for dev validation and testing
- main branch: deploy to upper environments, such as Test and Prod
IMPORTANT: Do not associate any artifact, i.e., Linked Services, Data Sets, etc., inside your Azure Data Factory solution to environment. When ADF exports the solution into Azure Resource Manager (ARM) template, it uses the exact naming and there is no out-of-the-box solution to rename. That’s mean if you name your Linked Services as ‘blobCsvMarketingDev‘, it will show up in Test and Prod as ‘blobCsvMarketingDev‘.
Once the Git integration is enabled, ADF artifacts are saved into the selected branch. You can find the artifacts are grouped by type into folders (screen capture on the left), and you can select your working branch or Switch to live mode, i.e., Dev environment (screen capture on the right):
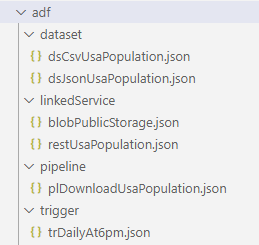
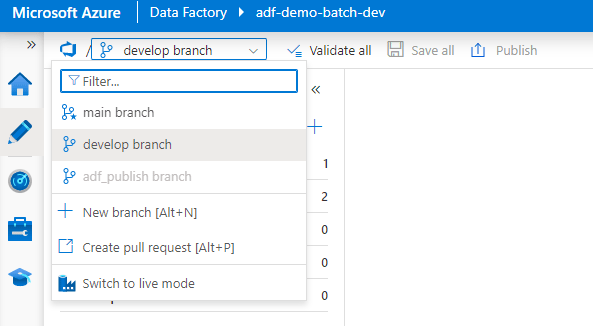
Last point, since ADF doesn’t have the concept of project or application, the deployment is all or nothing, i.e., no cherry pick unless you manually edit the exported ARM template. If there is a requirement for deploying individual or a group of artifacts, you should use another instance of ADF, as far as I know it won’t cost you extra.
Azure Data Factory: Build & Package
With the introduction of the ADF Utilities NPM package, you can now easily create CI/CD pipelines to validate (i.e., build) and export (i.e., package) the ADF artifacts. To start, we need a package.json file in the ADF ‘root’ folder to instruct the installation of NPM package (link to NPM site):
{
"scripts":{
"build":"node node_modules/@microsoft/azure-data-factory-utilities/lib/index"
},
"dependencies":{
"@microsoft/azure-data-factory-utilities":"^1.0.0"
}
}
In addition, I stored the latest pre/post deployment script from ADF Sample GitHub (link) in my repo so that I can easily add it to the deployment package. This script is required to stop Triggers prior to deployment and start them back after deployment. FYI, as the time of writing, it is PrePostDeploymentScript.Ver2.ps1.
The build-adf-app.yaml template (link) encapsulate the build and package for ADF artifact. It installs the NPM package first, and then perform either ‘validate’ or ‘export’ based on the needs (i.e., CI or CD). At last, both the generated ARM template, parameter files and necessary scripts are published into pipeline artifact.
Azure Data Factory: Deployment
Once the package is created, the deployment is handled by deploy-adf-app.yaml (link). It first stops the Triggers by calling the PrePostDeplooymentScript.Ver2.ps1 with predeployment parameter set to $true, then uses the az cli to deploy the ARM template, and finally, restarts the Triggers by providing $false for predeployment parameter.
- task: AzurePowerShell@5
displayName: 'Stop ADF triggers'
inputs:
azureSubscription: ${{parameters.serviceConnection}}
ScriptType: 'FilePath'
ScriptPath: $(armTemplatePath)/PrePostDeploymentScript.Ver2.ps1
ScriptArguments: -armTemplate "$(armTemplatePath)/ARMTemplateForFactory.json"
-ResourceGroupName "$(rg-full-name)"
-DataFactoryName "$(adf-full-name)"
-predeployment $true
-deleteDeployment $false
azurePowerShellVersion: 'LatestVersion'
pwsh: true
- task: AzureCLI@2
displayName: 'Provision Services (${{variables.targetEnvName}})'
inputs:
azureSubscription: ${{parameters.serviceConnection}}
scriptType: pscore
scriptLocation: inlineScript
inlineScript: |
az deployment group create --resource-group $(rg-full-name) --name 'main-$(Build.BuildNumber)' `
--template-file '$(armTemplatePath)/ARMTemplateForFactory.json' `
--parameters '$(armTemplatePath)/adf-param-files/adf-param-${{parameters.targetEnv}}.json'
- task: AzurePowerShell@5
displayName: 'Start ADF triggers'
inputs:
azureSubscription: ${{parameters.serviceConnection}}
ScriptType: 'FilePath'
ScriptPath: '$(armTemplatePath)/PrePostDeploymentScript.Ver2.ps1'
ScriptArguments: -armTemplate "$(armTemplatePath)/ARMTemplateForFactory.json"
-ResourceGroupName "$(rg-full-name)"
-DataFactoryName "$(adf-full-name)"
-predeployment $false
-deleteDeployment $false
azurePowerShellVersion: 'LatestVersion'
pwsh: true
Azure Data Factory: Configuration for different environments
When ADF generates the ARM template, it utilizes the arm-template-parameters-definition.json file to decide which properties should be parameterized. This file should be in the ADF folder (same as the package.json file). If the file doesn’t exist, it will use the default (MS Doc link). For example, the following parameter file is generated based on the default:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "adf-demo-batch-dev"
},
"blobPublicStorage_properties_typeProperties_serviceEndpoint": {
"value": "https://stdemobatchdev.blob.core.windows.net/"
},
"restUsaPopulation_properties_typeProperties_url": {
"value": "https://datausa.io/api/data?measures=Population"
}
}
}
Since the default template includes the serviceEndpoint under the linkedServices (see partial extract below), ADF generates it as parameter.
"Microsoft.DataFactory/factories/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
...
"serviceEndpoint": "=",
...
"mlWorkspaceName": "="
}
}
},
We can add our own parameters for any environment specific value. For example, if we need to customize the Retry count for different environments under the Copy Data activity inside a pipeline:
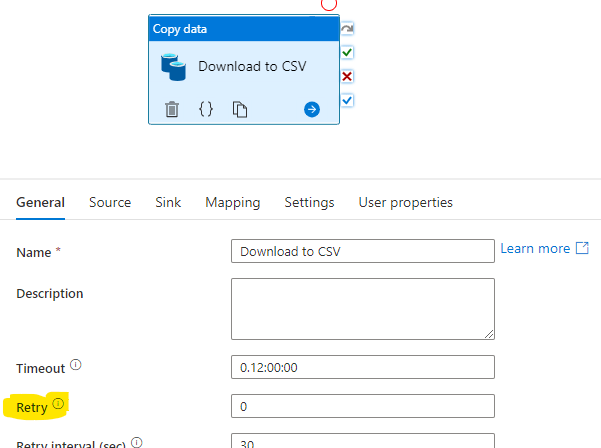
I first review the JSON source of the pipeline and find out ‘where’ is the properties:
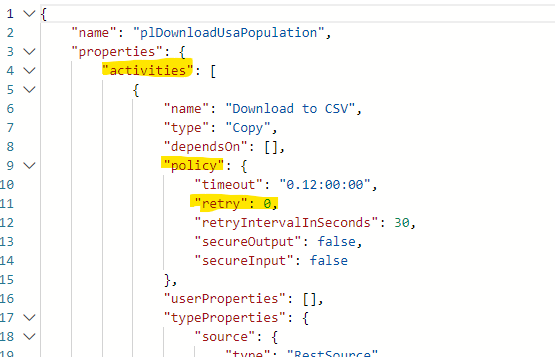
Then, update the arm-template-parameters-definition.json according to hierarchy, and use the syntax documented in Microsoft documentation (MS Doc link). In the example below, I reuse the existing value as default by providing the “=“, shortening the parameter name with “–” to CopyRetry, and indicate the data type is int:

Once updated, ADF generates the ARM template with an additional parameter for all activities that have a Retry count properties under Policy for any pipeline:

I use the generated parameter file, ARMTemplateParametersForFactory.json, as the base to create parameters file for Test and Prod, and store them under a folder, adf-param-files, so that they can be easily packaged for deployment.
Closing out
This recipe covers the fundamental for Azure Data Factory CI/CD using YAML pipeline and customizing configuration for different environments. I will cover more details, such as Integration Runtime, using a ‘private’ scenario in upcoming post. As usual, please let me know if you have any suggestion to improve documenting the recipe or structuring the sample code.
