This post is a continuation of batch scenario for line-of-business (LOB) application: extract-transform-load (ETL) or extract-load-transform (ELT). The previous post is for ‘public’ access, Azure Data Factory CI/CD (Public) (link), and this post is for ‘private’ access to Azure resources Azure Data Factory Batch Job (Private Endpoint):
- Application has no access endpoint and runs on background in a preset interval
- Business logic processing is not required (or limited) *
- Data sources and targets are hosted in Azure Services such as Storage Account
- Data sources and targets are only internal accessible
- Data sensitivity is medium, which has some impact to the organization
*If business logic processing is required, Azure Functions could be a better choice for encapsulating and/or reusing existing business layer components, please refer to Azure Function Batch Job with Storage Account (link).
Here are the areas I would like to demonstrate in this recipe:
- Use Azure Data Factory to run batch job using Managed Virtual Network
- Access Azure resources within private network via Private Endpoint from ADF
- Automate approval of ADF Managed Private Endpoint
- Use Key Vault to store sensitivity information
- Demonstrate CI/CD automation with Azure DevOps using Bicep and YAML
You can find all the code in GitHub (link).
Application Example
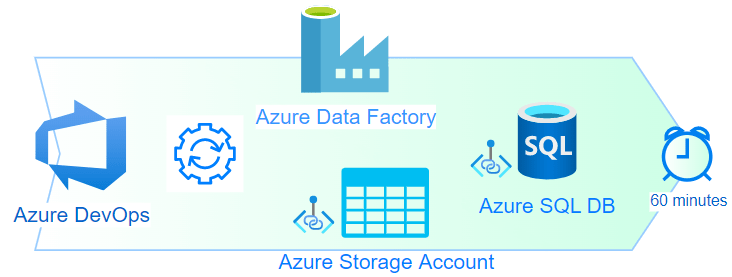
As an example, this batch job is to import contact information into central contact database once an updated file is provided. The implementation is to use an Azure Data Factory with Storage Event Trigger (requires Microsft.Event Grid provider registered in the subscription) to load the CSV file from Storage Blob and insert into SQL database. Below diagram shows the deployment model into Azure Cloud:

Walkthrough
Azure Data Factory: Managed Virtual Network
Azure Data Factory utilizes Managed Virtual Network to access Azure resources locked down by Private Endpoint, which provides the benefit of offloading the burden of the virtual network and related artifacts to Azure Data Factory. The ‘managed’ approach comes with limitations and not as flexible as VNet Integration for Azure App Services (MS Doc link). For example, data sources or services must be natively support private endpoint, if not we need to work around it.
To enable this feature, we need a Managed Virtual Network (must be named as default), an Azure Integration Runtime (IR) and link them together. In the recipe, I use the out-of-the-box AutoResolveIntegrationRuntime instead of creating an extra Integration Runtime. If you need the IR in a specific region, then you need to create your own because the location for out-of-the-box IR must be ‘auto resolve’.
resource managedVirtualNetwork 'Microsoft.DataFactory/factories/managedVirtualNetworks@2018-06-01' = if (enableManagedVNet) {
name: 'default'
parent: dataFactory
properties: {}
}
resource managedIntegrationRuntime 'Microsoft.DataFactory/factories/integrationRuntimes@2018-06-01' = if (enableManagedVNet) {
name: 'AutoResolveIntegrationRuntime'
parent: dataFactory
properties: {
type: 'Managed'
managedVirtualNetwork: {
referenceName: 'default'
type: 'ManagedVirtualNetworkReference'
}
typeProperties: {
computeProperties: {
location: 'AutoResolve'
dataFlowProperties: {
computeType: 'General'
coreCount: 4
timeToLive: 0
}
}
}
}
dependsOn: [
managedVirtualNetwork
]
}
CAUTION: If you set the Time To Live (TTL) other than zero, you will incur a minimum billing time of your TTL setting even though you are not using it.
We also need to enable Interactive Authoring (MS Doc link) in DEV environment to perform tasks like test connection, browse folder list, etc. Even though it can be done via ADF Studio, I want to automate it as well. Unfortunately, I cannot find any Bicep or az cli for enabling, and there is not even documented API. I ended up using the same API documented for Synapse (MS Doc link) to do the works. The enabling is added as a task in provision-infra.yaml (link) with the script shown below. Basically, the script first finds out the Integration Runtime Id from the deployment output, then call the REST API:
$outputs = (az deployment group show --resource-group $(rg-full-name) --name 'main-$(Build.BuildNumber)' `
--query "{irId:properties.outputs.defaultIrId.value}") | ConvertFrom-Json
$apiUrl = "https://management.azure.com$($outputs.irId)/enableInteractiveQuery?api-version=2018-06-01"
echo $apiUrl
az rest --url $apiUrl --method 'POST' --body '{ "autoTerminationMinutes": 30 }'
Azure Data Factory: Managed Private Endpoint
Managed Private Endpoints are provisioned for each locked-down Azure resources: Storage Account, Key Vault and SQL server. The Bicep module, data-factory-managed-pep.bicep (link), is used, which is relatively straight forward as you can see below:
resource dataFactory 'Microsoft.DataFactory/factories@2018-06-01' existing = {
name: dataFactoryName
}
resource managedVirtualNetwork 'Microsoft.DataFactory/factories/managedVirtualNetworks@2018-06-01' existing = {
name: managedVNetName
parent: dataFactory
}
resource peResource 'Microsoft.DataFactory/factories/managedVirtualNetworks/managedPrivateEndpoints@2018-06-01' = {
name: peName
parent: managedVirtualNetwork
properties: {
connectionState: {}
fqdns: [
privateDnsZoneName
]
groupId: peGroupId
privateLinkResourceId: resourceIdforPe
}
}
All the Managed Private Endpoints are provisioned as Pending, which should be approved by the resource owner. Since we are the owner, we can approve them manually or automate the approval as part of the pipeline, see below (link).
Azure Data Factory: Development Approach
For ‘private’ scenario, we have a few more preparation steps to set up the Dev environment prior to any development activity. To start, a dedicated pipeline is used to provision infrastructure including Azure Data Factory plus the Managed Virtual Network and Managed Private Endpoint according to the deployment model.
Once the provisioning completed, we need to sync the ADF Dev environment and the develop branch. When you first open ADF Studio, it prompts you to import the Managed Virtual Network, make sure this step is performed and ensure the target branch is develop:

Then, we need to import the Managed Private Endpoint artifacts as well by clicking on the Import resources link under the Git configuration:

The last preparation step is to ‘approve’ the managed private endpoints accordingly. I consider the approval process as part of the application deployment in case there are additional managed private endpoints created during the project cycle. To perform a deployment, we should first trigger the CI pipeline to ensure everything is validated and generate the ARM template with parameter file. Then, use the content of ARMTemplateParametersForFactory.json to populate our the ADF parameter files accordingly under the adf-param-files (link) folder.
Once completed, the CD pipeline can be triggered, which has a ‘new’ step for approval, see deploy-adf-app.yaml (link). The approval is handled by a script file, private-endpoint-approval.ps1: it reads the ADF parameter file to determine private endpoint resources, find out if there is any pending approval and approve them:
$param = Get-Content "adf-param-$targetEnv.json" | ConvertFrom-Json
$resourceList = $param.parameters | Get-Member | Where-object { $_.Name -like "*_privateLinkResourceId"} | Select-Object Name
foreach ($resource in $resourceList)
{
$resourceId = $param.parameters.($resource.Name).value
$pendingPe = (az network private-endpoint-connection list --id $resourceId `
--query "[?properties.privateLinkServiceConnectionState.status == 'Pending'].id" --output tsv)
foreach ($pe in $pendingPe) {
Write-Host 'Approving' $pe
az network private-endpoint-connection approve --id $pe --description 'Approved by CI/CD'
}
}
Besides these preparation steps, the development approach is the same as discussed in Azure Data Factory CI/CD Public (link). In other words, create all the required artifacts, Linked Services, Data Sets, Pipeline and Triggers, accordingly, use CI to validate and generate ARM template and parameter file.
IMPORTANT: Any development activity can add/update/delete ADF artifact parameters, make sure the parameter files under the adf-param-files folder are aligned with the generated one.
Closing out
This recipe covers the ‘managed’ approach for Azure Data Factory CI/CD using YAML pipeline to access private Azure resources. I will cover Self-Hosted Integration Runtime to allow boarder access to on-premises resources in upcoming post. As usual, please let me know if you have any suggestion to improve documenting the recipe or structuring the sample code.
